Machine learning đang trở thành một trong những công nghệ cốt lõi định hình kỷ nguyên số, từ trí tuệ nhân tạo, phân tích dữ liệu cho đến tự động hóa trong nhiều lĩnh vực. Đây không chỉ là xu hướng nhất thời, mà còn là nền tảng cho sự phát triển lâu dài của công nghệ thông tin và kinh doanh hiện đại. Hãy cùng CodeGym Đà Nẵng khám phá chi tiết hơn về Machine learning trong bài viết dưới đây để hiểu rõ cách nó vận hành và cơ hội nghề nghiệp hấp dẫn mà nó mang lại.
Xem thêm: Tham khảo khóa học Python/ Machine Learning tại CodeGym Đà Nẵng
Nội dung
Machine learning là gì?
Machine Learning (ML), hay còn gọi là Học máy, là một lĩnh vực trong khoa học máy tính tập trung vào việc khai thác dữ liệu và xây dựng thuật toán để giúp trí tuệ nhân tạo (AI) học hỏi giống con người, từ đó ngày càng nâng cao độ chính xác.
Theo định nghĩa kinh điển của Tom Mitchell trong cuốn Machine Learning (1997), một chương trình học máy có thể được hiểu như sau: chương trình được giao một nhiệm vụ T, trong quá trình thực hiện sẽ tích lũy trải nghiệm E. Dựa trên trải nghiệm này, chương trình có thể điều chỉnh cách thức hoạt động để xử lý các nhiệm vụ T+1 tốt hơn, với mục tiêu cuối cùng là cải thiện hiệu suất P.
Machine learning đang thay đổi cách con người xử lý dữ liệu và đưa ra quyết định trong mọi lĩnh vực, từ y tế, tài chính đến thương mại điện tử (Nguồn: Internet)
Quy trình triển khai thuật toán Machine learning
Quy trình xây dựng và triển khai một thuật toán Machine Learning thường trải qua 6 giai đoạn chính:
- Thu thập dữ liệu (Data collection): Đây là bước khởi đầu, nơi hệ thống cần có đủ dữ liệu để làm cơ sở cho toàn bộ quá trình học.
- Tiền xử lý dữ liệu (Data preprocessing): Dữ liệu thô cần được xử lý trước khi đưa vào mô hình, bao gồm:
- Trích xuất dữ liệu (Data extraction)
- Làm sạch dữ liệu (Data cleaning)
- Chuyển đổi dữ liệu (Data transformation)
- Chuẩn hóa dữ liệu (Data normalization)
- Trích xuất đặc trưng (Feature extraction)
- Phân tích dữ liệu (Data analysis): Khám phá, quan sát các mẫu, xu hướng và mối quan hệ trong dữ liệu.
- Xây dựng mô hình (Model building): Chọn và thiết kế thuật toán phù hợp cho bài toán.
- Huấn luyện mô hình (Model training): Cho mô hình “học” từ dữ liệu bằng cách điều chỉnh tham số để tối ưu hiệu quả.
- Đánh giá mô hình (Model evaluation): Kiểm tra và đo lường độ chính xác, khả năng tổng quát hóa của mô hình.
Trong toàn bộ quy trình, ba khâu quan trọng và tốn nhiều thời gian nhất là thu thập dữ liệu, tiền xử lý và xây dựng tập dữ liệu huấn luyện. Đây chính là nền móng quyết định chất lượng của mô hình. Nếu dữ liệu đầu vào không đầy đủ hoặc thiếu chính xác, thì dù thuật toán có tiên tiến đến đâu, kết quả cuối cùng vẫn khó đạt được độ tin cậy mong muốn.
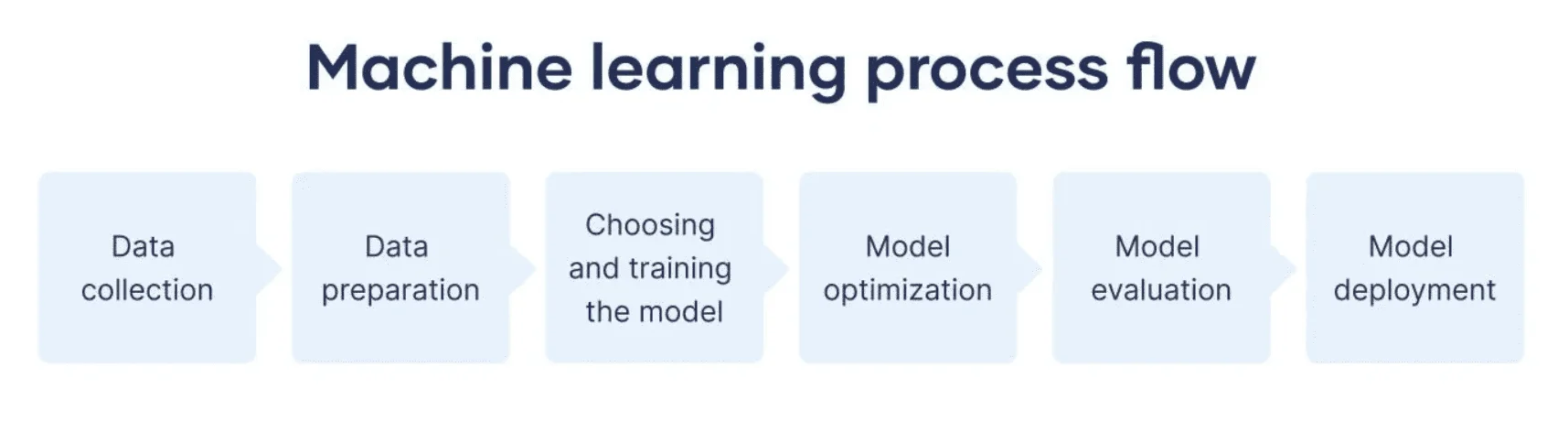
Quy trình triển khai thuật toán Machine learning gồm thu thập, xử lý dữ liệu, xây dựng, huấn luyện và đánh giá mô hình (Nguồn: Internet)
Phân loại các phương pháp Machine learning
Học có giám sát (Supervised learning)
Supervised learning (học có giám sát) là một phương pháp trong Machine Learning, nơi mô hình được “dạy” bằng các dữ liệu đã có nhãn sẵn. Nói cách khác, hệ thống sẽ học từ những cặp dữ liệu (input – dữ liệu đầu vào, label – nhãn/đầu ra mong muốn) để sau đó có thể dự đoán kết quả cho những dữ liệu mới chưa từng gặp.
Đây là dạng thuật toán được sử dụng phổ biến nhất trong học máy bởi tính trực quan và hiệu quả cao.
Ví dụ:
- Trong bài toán phân loại email spam, hệ thống được cung cấp nhiều email mẫu, mỗi email được gắn nhãn “spam” hoặc “không spam”. Sau khi học từ dữ liệu này, mô hình có thể dự đoán một email mới thuộc nhóm nào.
- Với dự đoán giá nhà, mô hình được huấn luyện bằng dữ liệu các ngôi nhà có sẵn thông tin (diện tích, số phòng, vị trí…) kèm giá bán thực tế (label). Từ đó, khi nhập dữ liệu của một căn nhà mới, hệ thống có thể ước tính giá trị của nó.
Học không giám sát (Unsupervised learning)
Unsupervised learning (học không giám sát) là một nhánh của Machine Learning, trong đó dữ liệu chỉ có đầu vào mà không có nhãn (outcome/label) đi kèm. Khác với supervised learning – nơi mô hình biết trước đáp án để học theo, thì với unsupervised learning, thuật toán phải tự khám phá cấu trúc tiềm ẩn trong dữ liệu.
Thông thường, unsupervised learning được áp dụng để:
- Phân nhóm dữ liệu (Clustering): Tự động gom các điểm dữ liệu có đặc điểm tương đồng vào cùng một nhóm.
- Giảm số chiều dữ liệu (Dimension reduction): Nén dữ liệu nhiều thuộc tính về dạng ít chiều hơn, giúp tối ưu lưu trữ và tính toán.
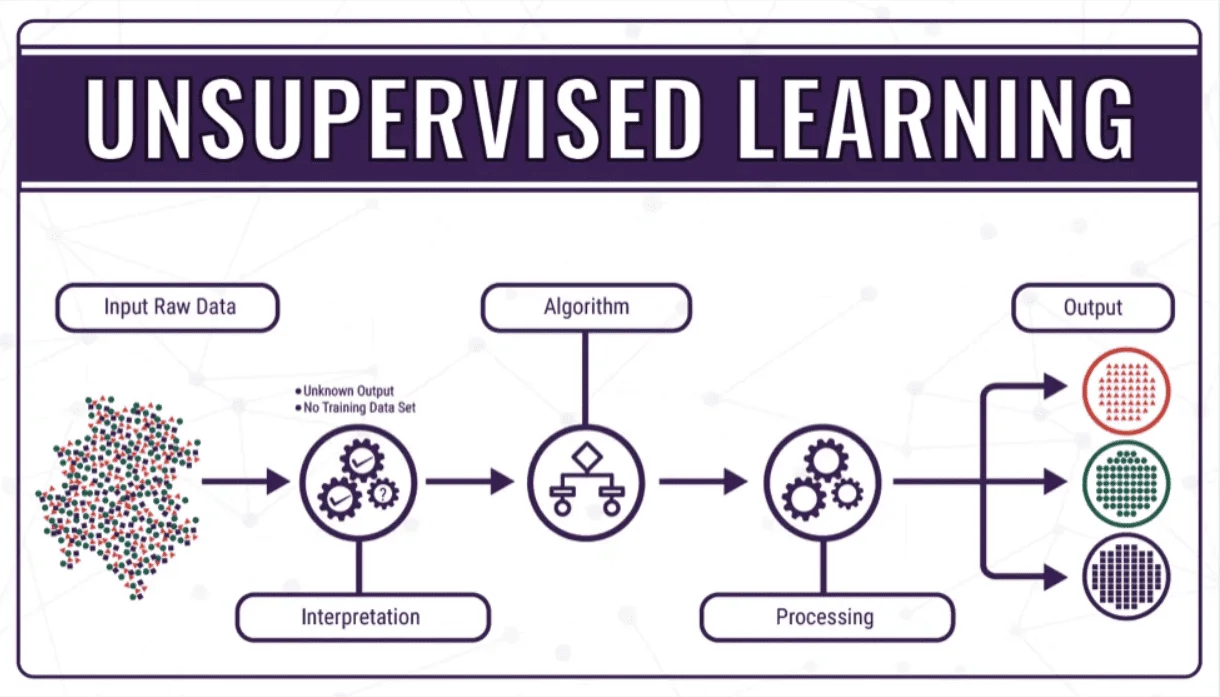
Học không giám sát giúp máy tính tự tìm ra cấu trúc và quy luật tiềm ẩn trong dữ liệu mà không cần nhãn có sẵn (Nguồn: Internet)
Ví dụ:
- Trong phân nhóm khách hàng (customer segmentation), doanh nghiệp sử dụng dữ liệu hành vi mua sắm (số lần mua hàng, loại sản phẩm, giá trị đơn hàng…) để hệ thống tự chia khách hàng thành từng nhóm khác nhau như: nhóm mua thường xuyên, nhóm chi tiêu cao, nhóm ít tương tác. Từ đó, công ty dễ dàng xây dựng chiến lược marketing phù hợp.
- Trong xử lý ảnh, kỹ thuật giảm chiều dữ liệu giúp nén ảnh mà vẫn giữ được những thông tin quan trọng, từ đó tăng tốc độ xử lý và tiết kiệm dung lượng lưu trữ.
Nói một cách đơn giản, unsupervised learning giống như việc ta tự học mà không có thầy cô hướng dẫn. Hệ thống phải tự tìm ra “quy luật” trong dữ liệu mà không có ai cho sẵn câu trả lời đúng.
Xem thêm:
- Tìm hiểu về Cấu trúc dữ liệu và giải thuật
- Lập trình AI là gì?
- AI Engineer là gì? Mô tả công việc và mức lương
Học bán giám sát (Semi-supervised Learning)
Semi-Supervised Learning (học bán giám sát) là một phương pháp trong Machine Learning áp dụng cho những bài toán mà chúng ta có một tập dữ liệu rất lớn, nhưng chỉ một phần nhỏ trong số đó được gán nhãn. Điều này khiến Semi-Supervised Learning trở thành “nằm giữa” Supervised Learning (có nhãn đầy đủ) và Unsupervised Learning (không có nhãn).
Ví dụ dễ hình dung: trong một dự án nhận diện hình ảnh, chỉ một số bức ảnh được gán nhãn rõ ràng như “người”, “động vật”, “cây cối”, trong khi phần lớn ảnh khác được thu thập từ internet lại chưa có nhãn. Hoặc trong xử lý ngôn ngữ tự nhiên, một số văn bản khoa học hay chính trị đã được phân loại, nhưng hàng triệu văn bản khác vẫn chưa được dán nhãn.
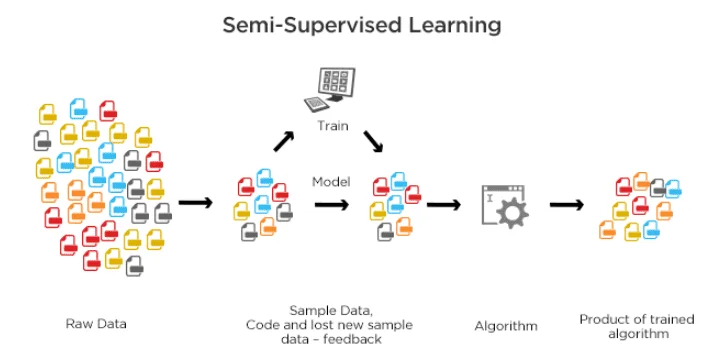
Học bán giám sát kết hợp dữ liệu có nhãn và không nhãn, giúp mô hình Machine learning đạt độ chính xác cao mà vẫn tiết kiệm chi phí gán nhãn (Nguồn: Internet)
Trên thực tế, Semi-Supervised Learning được ứng dụng rộng rãi vì dữ liệu có nhãn thường rất khó và tốn kém để thu thập. Nhiều lĩnh vực còn đòi hỏi chuyên gia để gán nhãn, chẳng hạn như ảnh y học. Trong khi đó, dữ liệu chưa gán nhãn có thể lấy từ internet với chi phí thấp. Bằng cách kết hợp cả dữ liệu có nhãn và không nhãn, Semi-Supervised Learning giúp tận dụng tối đa nguồn dữ liệu, đồng thời tiết kiệm thời gian và chi phí cho quá trình huấn luyện mô hình.
Học tăng cường (Reinforcement Learning)
Reinforcement learning (học tăng cường) là một phương pháp trong Machine Learning, nơi hệ thống tự động đưa ra quyết định về hành vi dựa trên bối cảnh để tối đa hóa lợi ích (maximize performance). Thay vì được “dạy” bằng dữ liệu có sẵn, hệ thống sẽ học thông qua việc thử – sai, nhận phản hồi từ môi trường dưới dạng “phần thưởng” (reward) hoặc “hình phạt” (penalty).
Ngày nay, Reinforcement learning không chỉ được ứng dụng trong lý thuyết trò chơi mà còn trong nhiều lĩnh vực như robotics, xe tự hành, tài chính, logistics…
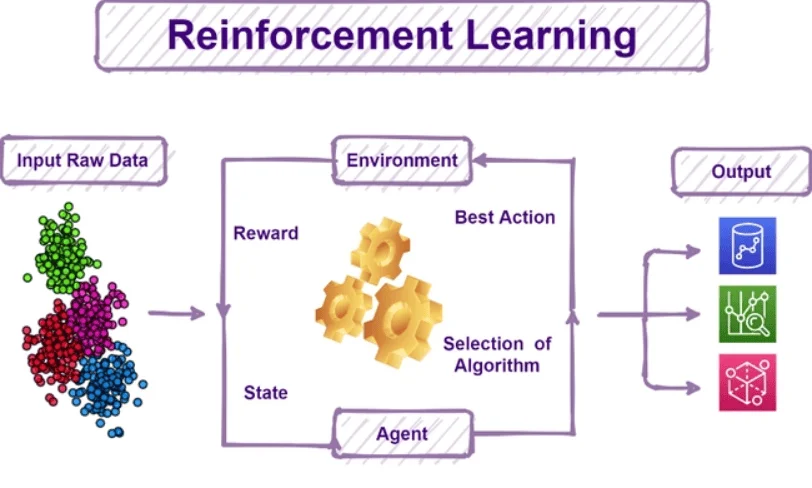
Học tăng cường cho phép hệ thống tự học thông qua cơ chế thử – sai, nhận thưởng hoặc phạt để dần tối ưu hành vi (Nguồn: Internet)
Ví dụ: trong xe tự lái, Reinforcement learning được sử dụng để hệ thống đưa ra quyết định tối ưu trong từng tình huống giao thông. Xe sẽ “học” cách xử lý các tình huống như rẽ trái, dừng đèn đỏ hay tránh chướng ngại vật dựa trên phản hồi từ môi trường. Nếu xe đi đúng luật và an toàn, mô hình nhận phần thưởng; ngược lại, nếu gây nguy hiểm, nó nhận hình phạt. Sau hàng triệu tình huống mô phỏng, hệ thống dần tối ưu hành vi lái xe để đảm bảo an toàn và hiệu quả.
Tương tự như AlphaGo trong trò chơi cờ vây, điểm mạnh của Reinforcement learning nằm ở việc cho phép hệ thống tự huấn luyện qua vô số lần thử nghiệm với chính nó hoặc môi trường giả lập. Điều này giúp phát hiện ra những chiến lược hoặc cách giải quyết mới mà con người chưa từng nghĩ tới.
Ứng dụng của Machine learning
Ứng dụng của Machine Learning trong đời sống và công nghệ rất đa dạng, có thể kể đến như:
- Hệ thống nhận diện hình ảnh trong camera giám sát hay mạng xã hội.
- Nhận diện giọng nói, hỗ trợ các công cụ như Google Assistant, Siri, Alexa.
- Dịch ngôn ngữ tự động giúp phá bỏ rào cản giao tiếp toàn cầu.
- Gợi ý sản phẩm trong thương mại điện tử, tối ưu trải nghiệm mua sắm.
- Xe tự lái có khả năng quan sát, phân tích và đưa ra quyết định an toàn trên đường.
- Bộ lọc email spam và mã độc, bảo vệ hộp thư người dùng.
- Trợ lý ảo thông minh hỗ trợ quản lý công việc, nhắc nhở lịch trình.
- Phát hiện gian lận trực tuyến trong thanh toán và ngân hàng.
- Tự động hóa giao dịch chứng khoán dựa trên phân tích dữ liệu lớn.
- Chẩn đoán bệnh lý y khoa, hỗ trợ bác sĩ trong việc phát hiện sớm các bệnh phức tạp.
- Phân tích cảm xúc và thái độ từ văn bản, bình luận mạng xã hội hoặc đánh giá khách hàng.
Phân nhóm các thuật toán Machine Learning
Các thuật toán Machine Learning thường được phân loại theo hai hướng chính: thứ nhất là dựa trên phương thức học (Learning style), và thứ hai là dựa trên chức năng (Function) mà thuật toán đảm nhận.
Dựa trên phương thức học
Các thuật toán Học có giám sát
Trong nhóm học có giám sát (Supervised Learning), các thuật toán thường được chia thành hai dạng chính:
- Classification (Phân loại): Đây là dạng bài toán mà dữ liệu đầu vào được gắn nhãn và phân vào một số nhóm hữu hạn. Ví dụ: hệ thống lọc thư rác của Gmail xác định email là “spam” hoặc “không spam”; công ty tài chính dự đoán khách hàng có “khả năng thanh toán” hay “không thanh toán”.
- Regression (Hồi quy): Khác với phân loại, hồi quy dự đoán nhãn là một giá trị số cụ thể. Chẳng hạn, với dữ liệu về diện tích, số phòng và vị trí, ta có thể dự đoán giá của một căn nhà.
Một ví dụ thú vị là ứng dụng dự đoán tuổi và giới tính dựa trên khuôn mặt: phần dự đoán giới tính thuộc Classification, trong khi phần dự đoán tuổi thuộc Regression. Tuy nhiên, nếu coi tuổi là số nguyên trong khoảng từ 1–150, thì nó cũng có thể được xử lý như một bài toán Classification với 150 lớp.
Các thuật toán học có giám sát phổ biến
- Linear Regression: Dùng trong các bài toán hồi quy, dự đoán giá trị liên tục dựa trên mối quan hệ tuyến tính giữa biến độc lập và biến phụ thuộc.
- Logistic Regression: Dùng trong phân loại nhị phân hoặc đa lớp, ước tính xác suất một đối tượng thuộc về một nhóm cụ thể.
- Decision Trees: Có thể áp dụng cho cả phân loại và hồi quy. Mô hình dạng cây giúp mô tả các quyết định và kết quả, dễ hiểu và trực quan.
- Random Forest: Tập hợp nhiều cây quyết định để tạo thành mô hình mạnh mẽ, tăng độ chính xác và giảm rủi ro quá khớp.
- Support Vector Machine (SVM): Dùng cho phân loại hoặc hồi quy. Thuật toán tìm ra siêu phẳng tối ưu để phân tách dữ liệu thành các nhóm, đồng thời tối đa hóa khoảng cách giữa các lớp.
- K-Nearest Neighbors (KNN): Dựa trên “người hàng xóm gần nhất”. Khi có dữ liệu mới, mô hình so sánh với các điểm lân cận để dự đoán nhãn hoặc giá trị.
- Naive Bayes: Một thuật toán phân loại dựa trên Định lý Bayes, giả định các đặc trưng độc lập với nhau. Rất phổ biến trong phân loại văn bản như email hay tin tức.
Các thuật toán Học không giám sát
Trong nhóm học không giám sát (Unsupervised Learning), các thuật toán thường được chia thành hai loại chính:
- Clustering (Phân cụm/Phân nhóm)
Clustering là quá trình chia tập dữ liệu X thành nhiều nhóm nhỏ (cluster) dựa trên sự tương đồng giữa các điểm dữ liệu.
Ví dụ: trong lĩnh vực bán lẻ, doanh nghiệp có thể phân nhóm khách hàng theo hành vi mua sắm để dễ dàng đưa ra chiến lược marketing phù hợp.
Hình dung đơn giản: bạn đưa cho một đứa trẻ nhiều mảnh ghép khác nhau về hình dạng (vuông, tròn, tam giác) và màu sắc (xanh, đỏ) nhưng không giải thích trước. Trẻ em thường có khả năng tự sắp xếp chúng thành từng nhóm theo hình hoặc màu – đây chính là cách Clustering hoạt động.
- Association (Luật kết hợp)
Association nhằm tìm ra các mối quan hệ tiềm ẩn trong dữ liệu để rút ra quy luật.
Ví dụ: khách hàng mua sữa thường có xu hướng mua kèm bánh mì; hoặc người xem phim Harry Potter thường quan tâm đến phim Chúa tể những chiếc nhẫn. Các mối liên kết này được ứng dụng phổ biến trong hệ thống gợi ý sản phẩm (Recommendation System) nhằm tăng trải nghiệm mua sắm và doanh thu.
Các thuật toán học không giám sát phổ biến
- K-Means Clustering: Chia dữ liệu thành K cụm dựa trên khoảng cách giữa các điểm và tâm cụm (centroid).
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Phân cụm dựa trên mật độ, có khả năng nhận diện các cụm có hình dạng bất kỳ và phát hiện điểm nhiễu.
- Hierarchical Clustering (Phân cụm phân cấp): Tạo cấu trúc cây, trong đó các cụm có thể được gộp lại hoặc tách nhỏ. Gồm hai hướng: Agglomerative (gộp dần) và Divisive (chia dần).
- PCA (Principal Component Analysis): Giảm số chiều dữ liệu, giữ lại phần lớn thông tin quan trọng để tối ưu tính toán và trực quan hóa.
- ICA (Independent Component Analysis): Tương tự PCA nhưng tập trung vào việc tìm ra các thành phần độc lập, thường dùng để tách tín hiệu (ví dụ: tách nhạc cụ trong bản ghi âm).
Các thuật toán Học bán giám sát
Các phương pháp Học bán giám sát (Semi-Supervised Learning) thường dùng bao gồm:
- Self-Training: Mô hình ban đầu được huấn luyện bằng một tập nhỏ dữ liệu có nhãn. Sau đó, nó dự đoán nhãn cho dữ liệu chưa có nhãn và chọn ra những dự đoán có độ tin cậy cao để bổ sung vào tập huấn luyện. Quy trình này được lặp lại nhiều vòng nhằm cải thiện độ chính xác.
- Co-Training: Kỹ thuật này triển khai hai mô hình khác nhau, mỗi mô hình học từ một góc nhìn hoặc tập đặc trưng riêng. Sau đó, chúng hỗ trợ lẫn nhau bằng cách gán nhãn cho dữ liệu không nhãn để mở rộng tập dữ liệu huấn luyện.
- Graph-Based Methods: Biểu diễn dữ liệu dưới dạng đồ thị, trong đó các điểm dữ liệu là đỉnh, còn các mối quan hệ tương đồng được biểu diễn bằng cạnh. Các nhãn sẽ được lan truyền từ dữ liệu có nhãn sang các điểm chưa có nhãn thông qua cấu trúc đồ thị.
- Label Propagation: Dựa trên nguyên lý đồ thị, nhãn từ dữ liệu có sẵn sẽ “truyền” dần sang dữ liệu chưa nhãn dựa trên mức độ giống nhau.
- Transductive Support Vector Machines (TSVM): Biến thể của SVM, tối ưu đường biên phân cách để cả dữ liệu có nhãn và không nhãn đều được phân chia hợp lý, giúp cải thiện khả năng phân loại.
- Entropy Minimization: Giảm thiểu độ “mơ hồ” trong dự đoán của mô hình bằng cách khuyến khích các nhãn được dự đoán với xác suất chắc chắn hơn.
- Pseudo-Labeling: Mô hình đầu tiên gán nhãn giả cho dữ liệu chưa nhãn, sau đó huấn luyện lại trên tập hợp bao gồm cả dữ liệu gốc có nhãn và dữ liệu mới với nhãn giả.
Các thuật toán Học tăng cường
Các thuật toán học tăng cường (Reinforcement Learning) phổ biến hiện nay có thể kể đến như:
- Q-Learning: Thuật toán học tăng cường không theo mô hình (model-free). Nó giúp tác nhân học được chính sách hành động tối ưu bằng cách tối ưu hàm giá trị Q, trong đó Q thể hiện “giá trị” của một hành động ở một trạng thái cụ thể.
- Deep Q-Network (DQN): Mở rộng từ Q-Learning, DQN sử dụng mạng nơ-ron sâu để xấp xỉ hàm giá trị Q. Nhờ đó, mô hình có thể xử lý được các không gian trạng thái lớn và liên tục, vốn khó với Q-Learning truyền thống.
- SARSA (State–Action–Reward–State–Action): Thuật toán này cập nhật trực tiếp giá trị Q dựa trên cặp trạng thái – hành động quan sát được từ chính sách hiện tại. Điểm khác biệt là SARSA gắn liền với chiến lược mà tác nhân đang sử dụng thay vì tối ưu lý thuyết.
- Policy Gradient Methods: Thay vì gián tiếp học qua giá trị Q, phương pháp này tối ưu trực tiếp chính sách. Mô hình điều chỉnh các tham số dựa trên gradient của hàm mục tiêu, hướng tới việc tăng xác suất nhận được phần thưởng cao.
- Actor–Critic Methods: Kết hợp hai ý tưởng: Actor dùng Policy Gradient để cập nhật chính sách, còn Critic ước tính giá trị trạng thái và đưa ra tín hiệu phản hồi giúp Actor điều chỉnh tốt hơn.
- Proximal Policy Optimization (PPO): Một thuật toán Policy Gradient ổn định. PPO sử dụng hàm mất mát đặc biệt để đảm bảo các bước cập nhật không vượt quá xa chính sách ban đầu, tránh tình trạng mất ổn định.
- Trust Region Policy Optimization (TRPO): Cũng thuộc nhóm Policy Gradient, TRPO giới hạn “khoảng cách” giữa các chính sách trước và sau cập nhật, nhằm đảm bảo quá trình học diễn ra mượt mà hơn, không thay đổi đột ngột.
- Deep Deterministic Policy Gradient (DDPG): Kết hợp ưu điểm của DQN và Policy Gradient để xử lý các bài toán có không gian hành động liên tục. DDPG sử dụng mạng nơ-ron sâu để vừa xấp xỉ giá trị vừa học chính sách.
- Soft Actor-Critic (SAC): Thuộc nhóm Actor–Critic nhưng bổ sung thêm cơ chế tối ưu entropy. Điều này khuyến khích tác nhân thăm dò nhiều hơn thay vì chỉ khai thác, từ đó tăng khả năng tìm ra hành động tốt nhất.
Xem thêm:
Dựa trên chức năng
Regression Algorithms
Ba dạng hồi quy thường gặp trong Machine Learning và thống kê gồm:
- Linear Regression (Hồi quy tuyến tính): Mô hình dự đoán mối quan hệ tuyến tính giữa biến độc lập và biến phụ thuộc, thường dùng để dự đoán các giá trị liên tục.
- Logistic Regression (Hồi quy logistic): Mặc dù mang tên “regression”, nhưng thuật toán này chủ yếu dùng cho các bài toán phân loại nhị phân hoặc đa lớp bằng cách ước lượng xác suất một đối tượng thuộc về một nhóm nào đó.
- Stepwise Regression (Hồi quy từng bước): Phương pháp chọn lọc biến độc lập dần dần để xây dựng mô hình tối ưu, thường dùng khi có nhiều biến và cần xác định đâu là những yếu tố ảnh hưởng quan trọng nhất.
Classification Algorithms
Các phương pháp phân loại phổ biến trong Machine Learning có thể kể đến như:
- Linear Classifier (Bộ phân loại tuyến tính): Phân chia dữ liệu bằng một đường thẳng hoặc siêu phẳng tuyến tính, thường dùng trong các bài toán đơn giản với dữ liệu có thể tách rời rõ ràng.
- Support Vector Machine (SVM): Thuật toán tìm siêu phẳng tối ưu để phân tách dữ liệu, đồng thời tối đa hóa khoảng cách giữa các nhóm, giúp mô hình phân loại chính xác hơn.
- Kernel SVM: Phiên bản mở rộng của SVM, sử dụng các hàm kernel để ánh xạ dữ liệu sang không gian có chiều cao hơn, từ đó xử lý hiệu quả các bài toán mà dữ liệu không tuyến tính.
- Sparse Representation-based Classification (SRC): Dựa trên biểu diễn thưa (sparse representation), trong đó một mẫu mới được biểu diễn như tổ hợp tuyến tính của một số ít mẫu huấn luyện, giúp nâng cao độ chính xác trong phân loại, đặc biệt hữu ích trong nhận dạng khuôn mặt và xử lý tín hiệu.
Instance-based Algorithms
Hai thuật toán phân loại dựa trên khoảng cách và vector tiêu biểu gồm:
- k-Nearest Neighbor (kNN): Thuật toán phân loại hoặc hồi quy dựa trên “những điểm láng giềng gần nhất”. Khi gặp một dữ liệu mới, mô hình sẽ xem xét k điểm dữ liệu gần nhất trong không gian và quyết định nhãn dựa trên đa số (trong phân loại) hoặc giá trị trung bình (trong hồi quy).
- Learning Vector Quantization (LVQ): Một phương pháp phân loại có giám sát, trong đó các vector mẫu (prototype vectors) được huấn luyện để đại diện cho từng lớp. Khi dữ liệu mới xuất hiện, mô hình sẽ gán nhãn dựa trên vector mẫu gần nhất, giúp việc phân loại trở nên trực quan và hiệu quả.
Regularization Algorithms
Ba kỹ thuật hồi quy thường được sử dụng để xử lý dữ liệu có nhiều biến độc lập gồm:
- Ridge Regression (Hồi quy Ridge): Phương pháp thêm một hệ số phạt vào hàm mất mát nhằm giảm hiện tượng đa cộng tuyến và ngăn mô hình overfitting, bằng cách thu nhỏ (shrinkage) giá trị các hệ số.
- Least Absolute Shrinkage and Selection Operator – LASSO (Hồi quy LASSO): Bên cạnh việc thu nhỏ hệ số, LASSO còn có khả năng loại bỏ hoàn toàn những biến ít quan trọng, nhờ đó vừa thực hiện hồi quy vừa chọn lọc đặc trưng.
- Least-Angle Regression (LARS – Hồi quy góc nhỏ nhất): Một thuật toán hiệu quả cho các bài toán có số biến độc lập lớn, hoạt động tương tự như phương pháp bước từng phần (forward stepwise), nhưng nhanh hơn và tối ưu hơn trong việc chọn biến.
Bayesian Algorithms
Hai biến thể phổ biến của thuật toán Naive Bayes gồm:
- Naive Bayes: Thuật toán phân loại dựa trên Định lý Bayes, với giả định rằng các đặc trưng trong dữ liệu là độc lập với nhau. Đây là phương pháp đơn giản nhưng rất hiệu quả, đặc biệt trong xử lý văn bản và lọc thư rác.
- Gaussian Naive Bayes: Là biến thể của Naive Bayes áp dụng cho dữ liệu liên tục, giả định rằng các đặc trưng tuân theo phân phối chuẩn (Gaussian distribution). Phù hợp với các bài toán như phân loại dựa trên đặc trưng số liệu thống kê hay dữ liệu cảm biến.
Clustering Algorithms
Ba phương pháp phân cụm thường gặp trong học máy gồm:
- k-Means Clustering: Thuật toán chia dữ liệu thành k cụm bằng cách tối ưu khoảng cách giữa các điểm dữ liệu và tâm cụm (centroid). Mỗi cụm đại diện cho một nhóm có đặc điểm tương đồng.
- k-Medians: Tương tự k-Means nhưng thay vì dùng giá trị trung bình để xác định tâm cụm, thuật toán sử dụng giá trị trung vị (median). Cách này giúp giảm ảnh hưởng của các điểm ngoại lai (outliers).
- Expectation Maximization (EM): Phương pháp lặp tối ưu nhằm ước lượng tham số trong các mô hình xác suất, thường dùng trong phân cụm dữ liệu phức tạp. EM xen kẽ giữa hai bước: Expectation (E-step) để tính toán xác suất thuộc cụm và Maximization (M-step) để cập nhật tham số mô hình.
Artificial Neural Network Algorithms
Các mô hình và kỹ thuật nền tảng trong học sâu (Deep Learning) có thể diễn giải như sau:
- Perceptron: Mô hình mạng nơ-ron đơn giản nhất, gồm một lớp đầu vào kết nối với một nút đầu ra. Perceptron thường được dùng cho các bài toán phân loại nhị phân cơ bản.
- Softmax Regression: Mở rộng của hồi quy logistic, được sử dụng cho các bài toán phân loại đa lớp. Thuật toán tính toán xác suất để một mẫu thuộc về từng lớp, sau đó chọn lớp có xác suất cao nhất.
- Multi-layer Perceptron (MLP): Là mạng nơ-ron nhân tạo nhiều lớp, bao gồm lớp đầu vào, một hoặc nhiều lớp ẩn, và lớp đầu ra. MLP có khả năng học các mối quan hệ phi tuyến phức tạp giữa dữ liệu đầu vào và đầu ra.
- Back-Propagation: Thuật toán cốt lõi để huấn luyện mạng nơ-ron. Nó hoạt động bằng cách lan truyền ngược sai số từ đầu ra về các lớp trước, từ đó điều chỉnh trọng số để giảm thiểu sai số dự đoán.
Dimensionality Reduction Algorithms
- Principal Component Analysis (PCA – Phân tích thành phần chính): Phương pháp giảm số chiều dữ liệu bằng cách tìm ra các thành phần chính (principal components) – những trục mới giữ lại phần lớn thông tin quan trọng, đồng thời loại bỏ nhiễu và dữ liệu dư thừa.
- Linear Discriminant Analysis (LDA – Phân tích biệt số tuyến tính): Kỹ thuật vừa giảm chiều vừa tối ưu khả năng phân tách giữa các lớp. LDA tìm ra không gian mới mà trong đó sự khác biệt giữa các nhóm dữ liệu được làm nổi bật, thường được dùng trong các bài toán phân loại.
Ensemble Algorithms
Ba kỹ thuật ensemble learning (học tập tổ hợp) thường dùng trong Machine Learning gồm:
- Boosting: Phương pháp kết hợp nhiều mô hình yếu (weak learners) theo tuần tự, trong đó mỗi mô hình mới sẽ tập trung vào các điểm dữ liệu mà mô hình trước đó dự đoán sai, từ đó dần cải thiện độ chính xác.
- AdaBoost (Adaptive Boosting): Một biến thể nổi tiếng của Boosting. AdaBoost gán trọng số cao hơn cho những mẫu bị phân loại sai và điều chỉnh lại mô hình để cải thiện kết quả cho các mẫu khó.
- Random Forest: Thuật toán kết hợp nhiều cây quyết định (Decision Trees) được xây dựng ngẫu nhiên. Kết quả cuối cùng được quyết định dựa trên việc bỏ phiếu (trong phân loại) hoặc trung bình (trong hồi quy), giúp mô hình ổn định và giảm nguy cơ quá khớp.
Machine learning đang dần trở thành nền tảng không thể thiếu trong kỷ nguyên công nghệ số, mở ra cơ hội phát triển nghề nghiệp rộng lớn cho những ai biết nắm bắt. Nếu bạn muốn bắt đầu con đường chinh phục Machine learning một cách bài bản và thực chiến, CodeGym Đà Nẵng chính là lựa chọn phù hợp. Hãy để lại thông tin để được tư vấn chi tiết và cùng bạn xây dựng lộ trình học hiệu quả ngay hôm nay!



0 Lời bình